TornadoVM Internals: Java APIs for Compiling Java methods to SPIR-V and running on GPUs via Level Zero
Published:
Key Takeaways
- Developers can use internal TornadoVM APIs to interact with the JIT compiler and the runtime system.
- The internal APIs are designed using a microkernel software architecture.
- This post shows how to use the internal APIs to interact directly with the TornadoVM JIT compiler interface and runtime system.
- This post targets system programmers that want to know more details about how to TornadoVM JIT compiler and runtime work.
TornadoVM is a Java parallel programming framework that allows developers to accelerate applications by transparently using heterogeneous hardware (e.g., GPUs, multi-core CPUs, and FPGAs).
TornadoVM offers high-level abstractions and APIs that facilitate programming through the creation and execution of task graphs (e.g., through the Task-Schedule API in version v0.14). Then, the TornadoVM runtime transforms and optimizes the task graphs into an internal list of bytecode that facilitates the orchestration of the whole program on the target accelerator (e.g., a GPU). The internal bytecode contains instructions for allocating buffers on the device, transferring data, and launching parallel kernels on heterogeneous hardware. In turn, TornadoVM implements all these actions by invoking internal APIs.
The internal APIs are designed in a microkernel software architecture. The microkernel is the core component that controls hardware resources and talks directly with the JIT compiler. Upon this core component, TornadoVM builds extensions for different backends and different programming models, such as Level Zero, SPIR-V, OpenCL or CUDA PTX.
Figure 1 shows the different levels of APIs across the software stack of TornadoVM. At the core level, TornadoVM has APIs for scheduling tasks, handling compilation and execution on different accelerators (named JIT Compiler API, device-execution API, and scheduling API as shown in Figure 1). The core APIs are automatically used by the Tornado Virtual Machine (TornadoVM), which contains a bytecode interpreter that handles the compilation and execution of Java methods on heterogeneous hardware. Besides, the TornadoVM compiles user applications that are expressed with the TornadoVM high-level API, which is composed of the Task-Schedule API, annotations and prebuilt API.
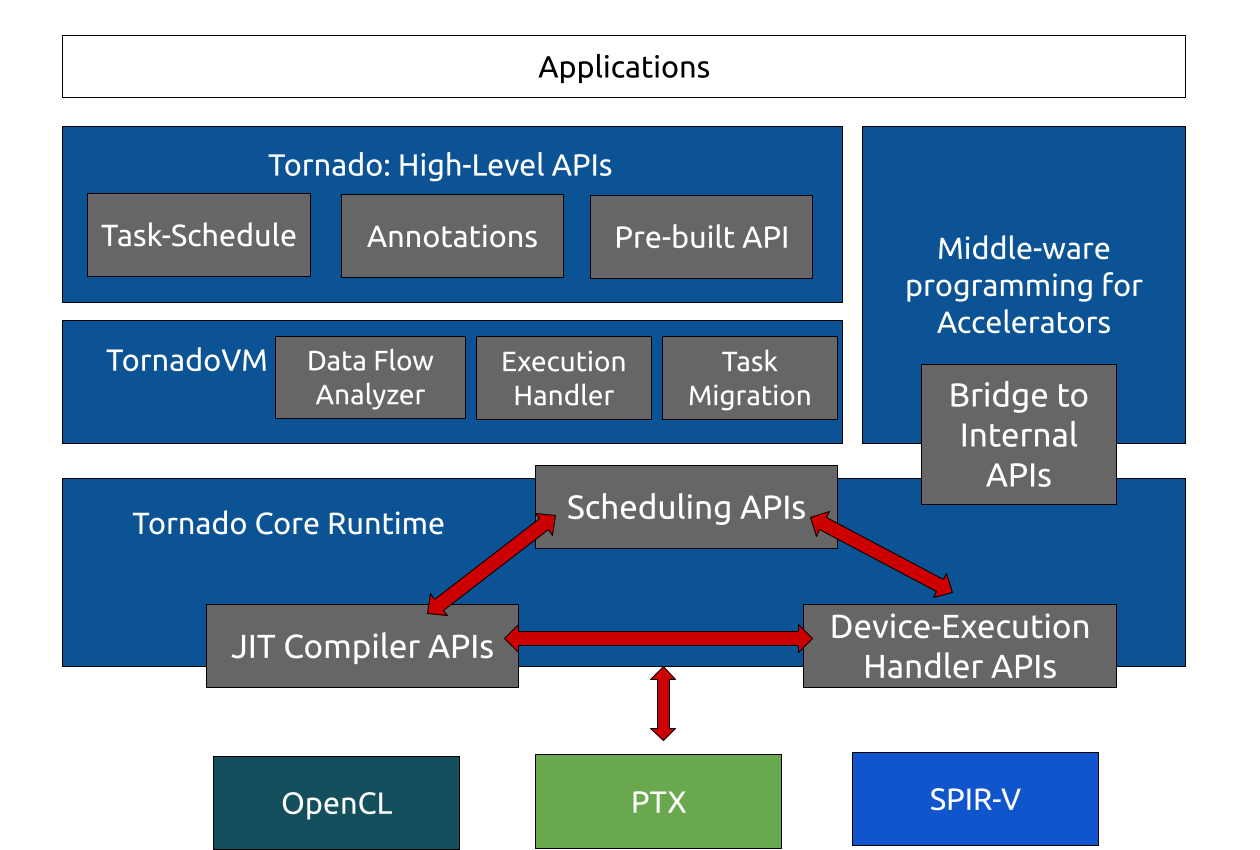
Figure 1: Microkernel Software Architecture of TornadoVM.
This post shows a way of how to interact with some of the core components of TornadoVM through these internal APIs, as shown in Figure 2. More specifically, it will show how to compile a Java method from the bytecode level to SPIR-V, and execute the generated binary on an Intel Integrated GPU.
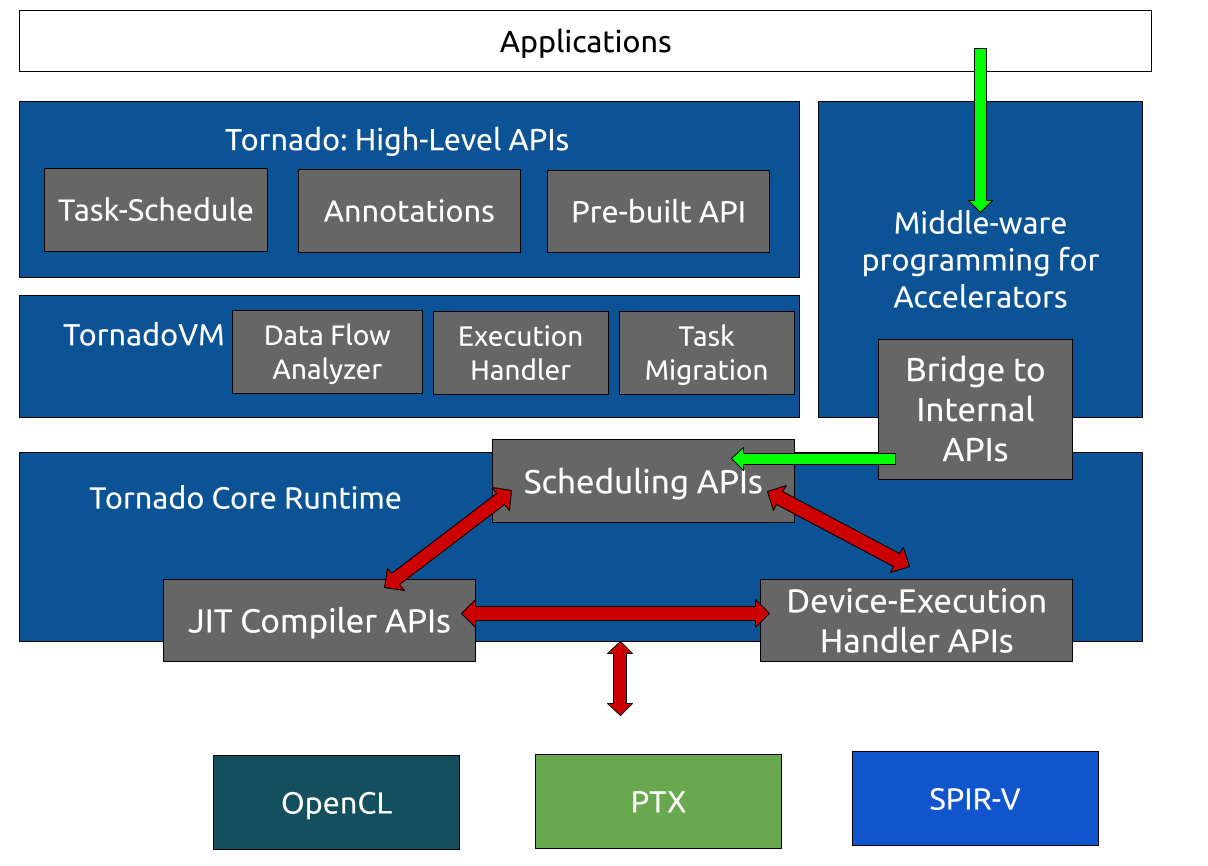
Figure 2: Highlights of the path taken to represent an application that directly uses the TornadoVM internal APIs.
To compile and execute Java code suitable for the target accelerator, we need two things: a) to compile the Java method to a GPU-friendly code (i.e., SPIR-V); and b) a way to reserve memory, allocate resources and launch kernels on the accelerator. In other words, we need a way to orchestrate the execution. Now, let’s explain each of those steps in more detail.
A) Interaction with the JIT compiler for translation of Java bytecode to SPIR-V.
To interact with the core API of the TornadoVM JIT compiler, we are going to build a function that transforms a Java method represented as an array of bytes into an optimized SPIR-V binary module. In pseudocode, we will need to implement a method with the following signature:
public ExecutableCode compileMethod(Class<?> klass, String methodName) {
...
}
However, TornadoVM compiles the code at runtime. And this creates more opportunities for optimizations, such as partially evaluating expressions, applying better loop unrolling, etc., if we know more information about the actual data used for execution. Thus, TornadoVM makes use of the input data to better optimize the code. Therefore, our signature is as follows:
public ExecutableCode compileMethod(Class<?> klass, String methodName, Object... data) {
...
}
Now, for the demonstration purposes, let’s compile the following Java method to SPIR-V:
public static void methodToCompile(int[] a, int[] b, double[] c) {
for (@Parallel int i = 0; i < c.length; i++) {
c[i] = 0.12 * a[i] * b[i];
}
}
The code snippet shows a Java method that performs a vector multiplication by a scalar value. Note the use of the @Parallel annotation. This annotation is exposed by TornadoVM to be used by programmers to indicate that a loop can be parallelizable. The TornadoVM JIT compiler can see this annotation and apply specific code transformation for generating parallel OpenCL, SPIR-V and PTX codes.
First, we need to get the core component of TornadoVM, the runtime. Through the runtime object of TornadoVM, we can have access to the Tornado JIT compiler.
// Get Tornado Runtime
TornadoCoreRuntime tornadoRuntime = TornadoCoreRuntime.getTornadoRuntime();
This object will help us to perform the following tasks:
- Build a sketcher for compilation. This is a special phase within the TornadoVM JIT compiler in which high-level optimizations are applied. Also, it performs data-flow analysis and loop parallelization exploration. The sketcher is common for all backends (OpenCL, SPIR-V and PTX).
- From the sketcher, then we want to build the GPU Intermediate Representation (IR), such as OpenCL C, PTX assembly code and SPIR-V. The result of this step is a compilation result object (e.g., SPIRVCompilationResult).
- Install the generated binary into the TornadoVM code cache. We install the final binary into the TornadoVM system. Besides, in this step, TornadoVM generates the final GPU/FPGA binary by invoking the underlying GPU/CPU and FPGA drivers for the target device. As a result, we get an instance of the InstalledCode class in JVMCI (e.g., SPIRVInstalledCode).
To build sketcher, we need to have access to the Graal Intermediate Representation (IR) of the method to be compiled. This can be done through the Java Method object as follows:
// Get the method object to be compiled
Method methodToCompile = CompilerUtil.getMethodForName(klass, methodName);
// Get the Graal Resolved Java Method
ResolvedJavaMethod resolvedJavaMethod = tornadoRuntime.resolveMethod(methodToCompile);
// Get the sketcher
Providers providers = spirvBackend.getProviders();
TornadoSuitesProvider suites = spirvBackend.getTornadoSuites();
Sketch sketch = buildSketchForJavaMethod(resolvedJavaMethod, taskMeta, providers,
Through the sketcher object, we can access the Graal IR of the method that is being compiled. Once we have an instance of an installed code, we can execute the code. We explain how to launch the code in the next Section. But before showing this, let’s look at the Java code of how steps 1-3 are performed.
public MetaCompilation compileMethod(Class<?> klass, String methodName, Object... data) {
// Get the method object to be compiled
Method methodToCompile = CompilerUtil.getMethodForName(klass, methodName);
// Get Tornado Runtime
TornadoCoreRuntime tornadoRuntime = TornadoCoreRuntime.getTornadoRuntime();
// Get the Graal Resolved Java Method
ResolvedJavaMethod resolvedJavaMethod = tornadoRuntime.resolveMethod(methodToCompile);
// Get the backend from TornadoVM
SPIRVBackend spirvBackend = tornadoRuntime.getDriver(SPIRVDriver.class).getDefaultBackend();
// Obtain the SPIR-V device
TornadoDevice device = tornadoRuntime.getDriver(SPIRVDriver.class).getDefaultDevice();
// Create a new task for TornadoVM
ScheduleMetaData scheduleMetaData = new ScheduleMetaData("s0");
// Create a compilable task
CompilableTask compilableTask = new CompilableTask(scheduleMetaData, "t0", methodToCompile, data);
TaskMetaData taskMeta = compilableTask.meta();
taskMeta.setDevice(device);
// 1. Build Common Compiler Phase (Sketcher)
Providers providers = spirvBackend.getProviders();
TornadoSuitesProvider suites = spirvBackend.getTornadoSuites();
Sketch sketch = buildSketchForJavaMethod(resolvedJavaMethod, taskMeta, providers, suites);
// 2. Function f: Sketch -> SPIR-V Compiled Code
SPIRVCompilationResult spirvCompilationResult = SPIRVCompiler.compileSketchForDevice(sketch, compilableTask, (SPIRVProviders) spirvBackend.getProviders(), spirvBackend, new EmptyProfiler());
// 3. Install the SPIR-V code into the VM
SPIRVDevice spirvDevice = (SPIRVDevice) device.getDeviceContext().getDevice();
SPIRVInstalledCode spirvInstalledCode = (SPIRVInstalledCode) spirvDevice.getDeviceContext().installBinary(spirvCompilationResult);
return new MetaCompilation(taskMeta, spirvInstalledCode);
}
B) Execute the generated code under the TornadoVM Runtime APIs.
To execute the generated code on a GPU, we need to allocate a GPU buffer for each Java input array, perform data transfers (send the data from the main CPU to the GPU), create a call stack, launch the kernel and transfer the result back from the GPU to the CPU. However, depending on the parallel programming model underneath, this can lead to the writing of a lot of boilerplate code. This process is particularly verbose when dispatching SPIR-V code within TornadoVM, which is implemented using the Level Zero API (a close bare-metal API for managing heterogeneous resources).
The TornadoVM core runtime component has abstracted away many of the low-level features1, allowing us to orchestrate the execution in a much simpler way. The TornadoVM code to launch a SPIR-V kernel is presented beneath:
public void run(SPIRVTornadoDevice spirvTornadoDevice, SPIRVInstalledCode installedCode, TaskMetaData taskMeta, int[] a, int[] b, double[] c) {
// First, we allocate, A, B and C
GlobalObjectState stateA = new GlobalObjectState();
DeviceObjectState objectStateA = stateA.getDeviceState(spirvTornadoDevice);
GlobalObjectState stateB = new GlobalObjectState();
DeviceObjectState objectStateB = stateB.getDeviceState(spirvTornadoDevice);
GlobalObjectState stateC = new GlobalObjectState();
DeviceObjectState objectStateC = stateC.getDeviceState(spirvTornadoDevice);
spirvTornadoDevice.allocateBulk(new Object[] { a, b, c }, 0, new TornadoDeviceObjectState[] { objectStateA, objectStateB, objectStateC });
// Copy-IN A
spirvTornadoDevice.ensurePresent(a, objectStateA, null, 0, 0);
// Copy-IN B
spirvTornadoDevice.ensurePresent(b, objectStateB, null, 0, 0);
// Create call stack wrapper for SPIR-V with 3 arguments
KernelArgs callWrapper = spirvTornadoDevice.createCallWrapper(3);
callWrapper.setKernelContext(new HashMap<>());
// Add kernel arguments to the SPIR-V Call Stack
callWrapper.addCallArgument(objectStateA.getObjectBuffer().toBuffer(), true);
callWrapper.addCallArgument(objectStateB.getObjectBuffer().toBuffer(), true);
callWrapper.addCallArgument(objectStateC.getObjectBuffer().toBuffer(), true);
// Launch the generated kernel
installedCode.launchWithoutDependencies(callWrapper, null, taskMeta, 0);
// Transfer the result from the device to the host (this is a blocking call)
spirvTornadoDevice.streamOutBlocking(c, 0, objectStateC, null);
}
The whole source code for this example can be found in the TornadoVM source repository.
We can run this program with the following options to check the generated SPIR-V code, and the parameters used to dispatch the generated kernel on an Intel Integrated GPU.
$ tornado \
--threadInfo \
--printKernel \
uk.ac.manchester.tornado.drivers.spirv.tests.TestSPIRVJITCompiler
MagicNumber: 0x7230203
; Version: 1.2
; Generator ID: 32
; Bound: 96
; Schema: 0
OpCapability Addresses
OpCapability Linkage
OpCapability Kernel
OpCapability Float64
OpCapability Int64
... // Rest of the SPIR-V Code
Task info: s0.t0
Backend : SPIRV
Device : SPIRV LevelZero - Intel(R) UHD Graphics [0x9bc4] GPU
Dims : 1
Global work offset: [0]
Global work size : [128]
Local work size : [128, 1, 1]
Number of workgroups : [1]
Conclusions
This post has shown an overview of the TornadoVM software architecture and some of its core software components along with the software stack. Furthermore, it has shown how TornadoVM builds the core APIs in a microkernel software architecture, allowing developers and system programmers to compose different levels of APIs. Through these core APIs, this post has explained how to compile at runtime Java methods to SPIR-V and execute the resulting binary code from Java.
As a side note, although the core APIs can be used from the user level, it is not recommended as they introduce boilerplate code. However, these low-level APIs of TornadoVM help to build abstractions on top, such as the Task-Schedule API and the graph execution handler. Hopefully, through this post, the reader can get a better idea about how TornadoVM handles compilation and execution.
Acknowledgements
I want to thank Athanasios Stratikopulos from The University of Manchester for the constructive feedback and fruitful debates on this post.
These internal API do not specify the type of the device to use. We only request a SPIR-V device because the code was already compiled for SPIR-V. Therefore, this API at this level of abstraction works for any accelerator (GPU, CPU and FPGA) that TornadoVM can handle. ↩